
Hazelcast-based inverted indexing.
- Category: Backend
- Client: Academic
- Project URL: Hazelcast-based inverted indexing
Summary
The project is built using Hazelcast, Java and JSCH
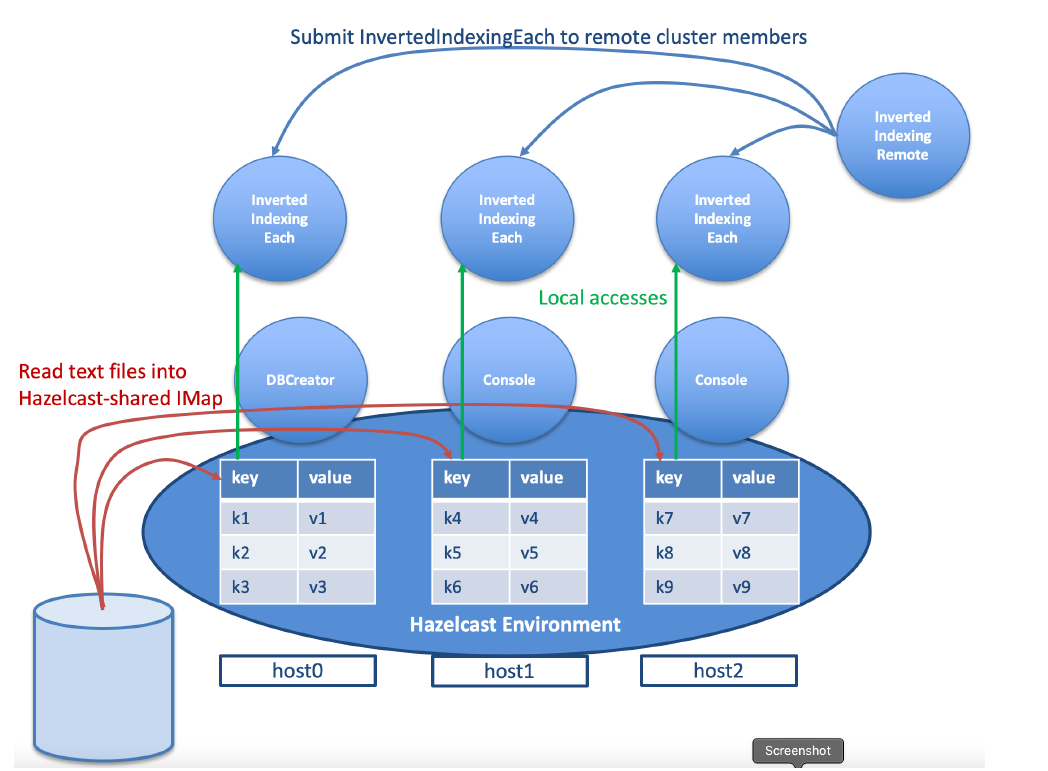
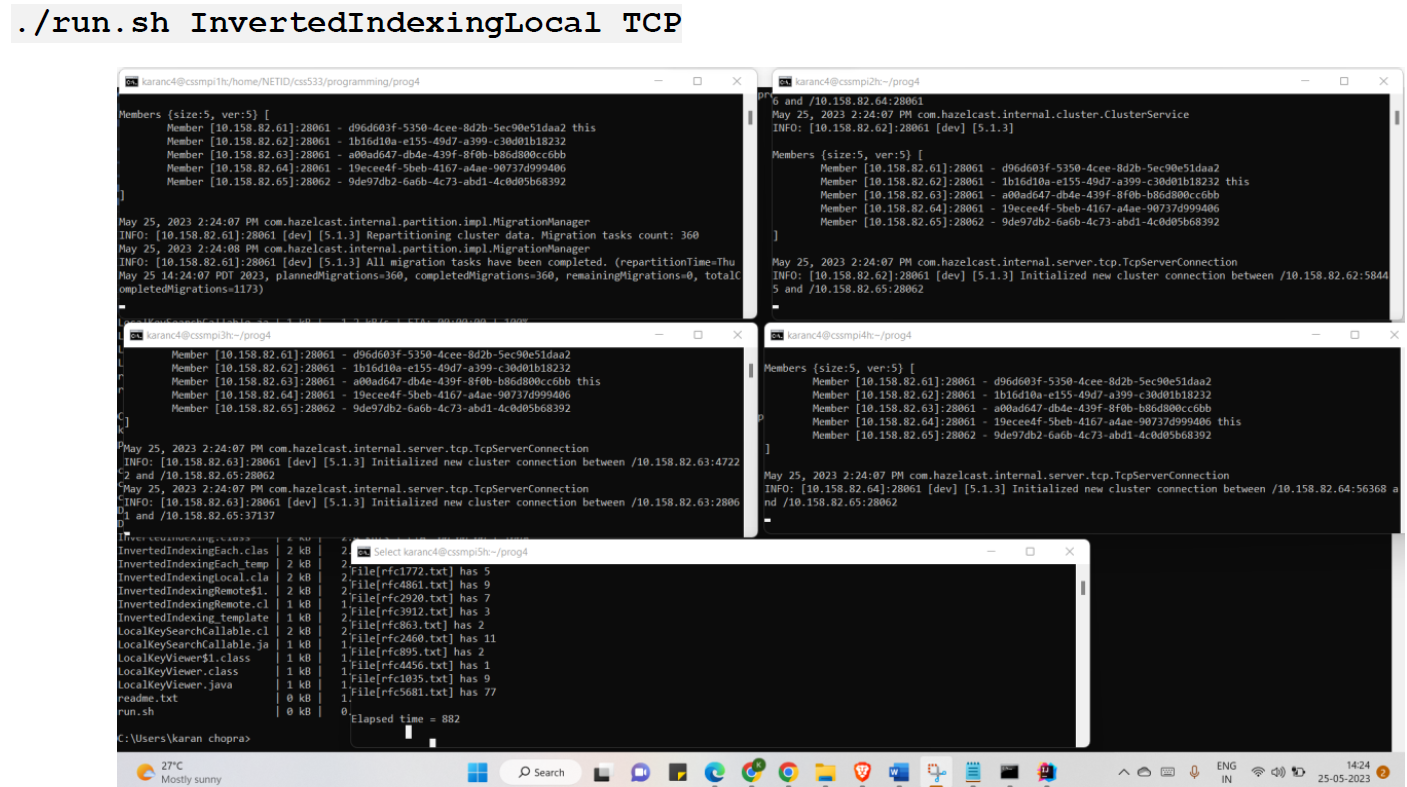
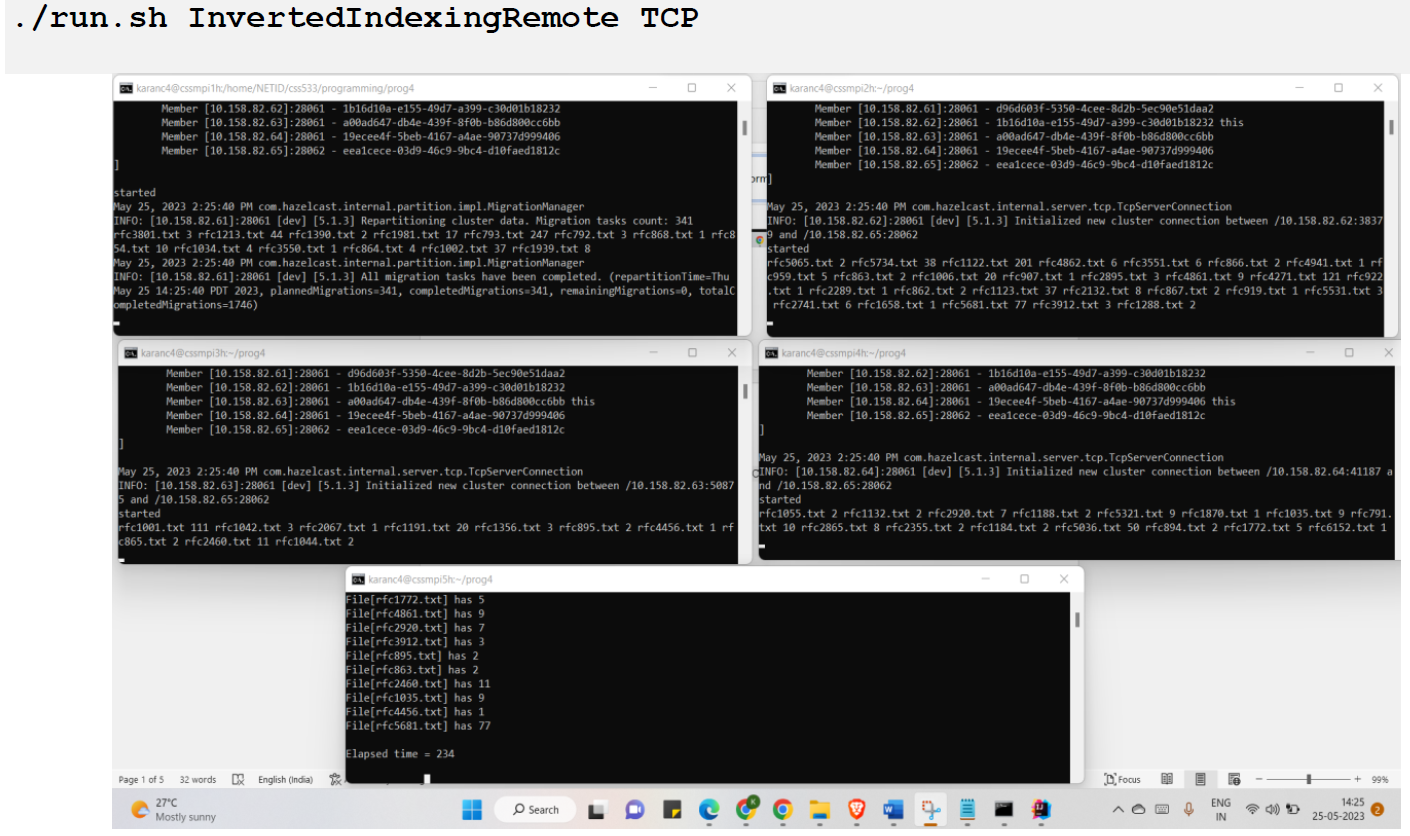
This assignment involves two versions of an inverted indexing program using Hazelcast's distributed map. The first version, counts word occurrences in each file, displaying file names and counts. The second version uses remote execution to count word occurrences in local files on each cluster node, aiming to explore Hazelcast's remote execution mechanism and measure performance.
This project implements two versions of inverted indexing program using Hazelcast’s distributed map that maintains a database of
Limitations: Topology Hardcoding: Current implementation hardcodes the cluster topology based on IP addresses, limiting flexibility and scalability. Single-Point-of-Failure: Reliance on a single Hazelcast instance as the central coordination point poses a risk of system failure if it becomes unavailable.
.